- Setup
- Interpretation
- Assumptions and consequences
- Checking assumptions
- Prediction and confidence intervals
- Graphics; scatterplot, residual plot, normal quantile plot.
Plan.
The basics.
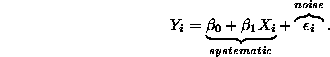
![]()
Range of feasible values should reflect uncertainty in the true regression line.
![]()
Range of feasible values should reflect uncertainty in the true regression line AND the variability of the points about the line.
From pages 92 and 96.
Measure With outlier Without outlier
R-squared 0.78 0.075
RMSE 3570 3634
Slope 9.75 6.14
SE(slope) 1.30 5.56
Examples
 Cleaning.jmp p9,59.
Cleaning.jmp p9,59.
Display.jmp p14,101.
Cottages.jmp p80
Direct.jmp p74
Phila.jmp p64