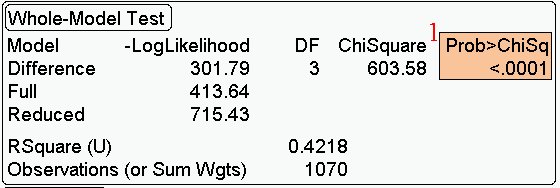
1. The overall test in logistic regression. Is anything going
on, are any (any combination) of the predictors useful in
predicting Y (the logits of the probabilities)? In this case the
small p-value indicates that this
is the case.
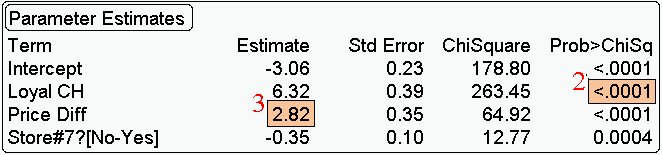
2. Is a specific coefficient significant (useful) after having
controlled for the other variables in the model. The small p-value
says this is indeed the case.
3. What does the 2.82 tell you?
For every 1 unit change in price diff the logit of the probability
of buying CH changes by 2.82. (controlling for loyal ch and store 7.)
BETTER. For every one unit (ie a dollar) change in
price diff the
odds of buying CH changes by a multiplicative factor of exp(2.82)
= 16.8.
Key calculation. At Loyal CH of 0.8, price diff of 20 cents
and product sold in store 7, predict the probability of buying CH?