


Next: 3.
Up: Stat701
Previous: 1.
The model for the mean relationship:
The model for the raw data:
This is the straight line or linear model.
Assumptions are on the
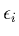 .
.

- Independent
-
- Constant variance. Mean zero.
-
- Approximately normally distributed.
Biggest problems. Dependence, skewness and non-constant variance.

- Call the
the "true error terms".
-
- Distance from point to the true line.
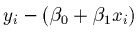 .
.
-
- We don't know them as we don't know the regression line.
-
- Substitute with the "residuals", estimated error terms.
-
- Distance from point to estimated regression line.
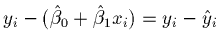 .
.
ALWAYS check assumptions on the residuals.
Why so important?
-
- Standard least squares regression is sensitive to individual data points.
-
- A single point can dominate the regression.
-
- Everything you say and conclude
may be driven by a single data point.
-
- Residual plots are one of the tools
available to help identify these points.
-
- Even if you keep it, it is important to know that it is there.
-
- Inference, p-values, CI's etc only has validity if assumptions hold.
Key diagnostics.
1. Residual plot. Good plots lack structure.
2. Normal scores plot of the residuals.
Next: 3.
Up: Stat701
Previous: 1.
Richard Waterman
1999-09-13