Stat 601, Fall 2001, Class 3

- The standard error of the sample mean;
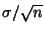 .
It measures how accurate the sample mean is as an estimate of the
population mean. No confusion - always use the formula (don't use the
standard deviation of sample means)
.
It measures how accurate the sample mean is as an estimate of the
population mean. No confusion - always use the formula (don't use the
standard deviation of sample means)
-
- The Central Limit Theorem
-
- Tracking sample means and standard deviations: x-bar and s-charts.
Setting control limits
-
- Confidence intervals - revue
-
- Sampling
-
- Decision making
-
- What are they?

- 1. A range of feasible values for an unknown population parameter, e.g.
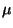 or
or 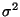
-
- 2. A statement conveying the confidence that the range of feasible values really does include the unknown population value. Confidence is understood to mean ``if I created 100 such intervals, how many of them would I expect to cover the true but unknown parameter''
-
- Where does it come from?
-
- Inverting the Empirical rule
-
- If 95% of the time the sample mean is within +/- 2 standard errors from ,
then 95% of the time the true
is within +/- 2 standard errors from the sample mean
-
- Why is it important?
-
- Move away from a single ``estimate'' to a range of values, which is more realistic
-
- Get to make the meta-level statement - our confidence
about the first statement
-
- Three assumptions (p.102)
-
- Observations are independent
-
- Approximately normal (less important the more observations you have)
-
- Constant variance
-
- How do I use it to make a decision?
-
- Example (p. 97), is 812 a feasible value for the true mean?
-
- Answer: look to see if 812 lies in the confidence interval
-
- If it's in the interval then it's a feasible value
-
- If it's outside the interval then it is not feasible
 ShaftXtr.jmp A confidence interval for the population mean.
ShaftXtr.jmp A confidence interval for the population mean.
CompPur.jmp A confidence interval for the intent to purchase.
-
- Context; there is a target population -
the group you wish to make inferences about. You draw a sample.
Use the sample to make statements about the population.
-
- Sample must be representative of the population
-
- Sampling is the way to obtain reliable information in a cost
effective way (why not census?)
-
- Objective; collect information. Issues:
-
- What to measure?
-
- How accurate do we need it?
-
- How often do we need it?
-
- Does it meet end user requirements?
-
- Representativeness
-
- Interviewer discretion
-
- Respondent discretion - non-response
-
- Key question: is the reason for non-response related to the
attribute you are trying to measure? Illegal aliens/Census.
Start-up companies/not in phone book.
-
- Good samples;
-
- Good samples; probability samples;
each unit in the population has a known
probability of being in the sample
-
- Simplest case; equal probability sample, each unit has the same
chance of being in the sample
-
- Bad samples - the rest, convenience samples
-
- You have a complete and accurate list of ALL the units in the
target population (sampling frame)
-
- From this you draw an equal probability sample (generate a list of
random numbers)
-
- Reality check; incomplete frame, impossible frame, practical
constraints on the simple random sample (cost and time of sampling)
-
- How large a sample do I need? p.115
-
- Focus on confidence interval - choose coverage rate (90%, 95%,
99%) margin of error (half the width). Typically trade off width
against coverage rate.
-
- Simple rule of thumb for a population proportion - if it's a 95% CI then use n = 1/(margin of error)**2.
Survey1.jmp A hotel customer satisfaction survey.
-
- Deciding on one of two choices
-
- Null hypothesis: status quo
-
- Alternative hypothesis: the converse of the null
-
- Example; jury trial. Null is
Innocent. Alternative is Guilty
-
- Note - one is taken as true a priori
-
- Decision based on collecting data - the jury votes.
If jury votes = 12 then convict else acquit and declare
NOT GUILTY. Note, do not declare innocent!
-
- Two types of error
-
- Innocent, but declare guilty (null true but go with alternative
- Type I)
-
- Guilty, but say innocent (alternative true but go with null -
Type II)
-
- Price of the errors? Which is worse (think capital trial)
-
- What should error rates be?
-
- Beyond all reasonable doubt - very small chance of incorrectly declaring guilty - small chance of a Type I error
-
- The preponderance of the evidence
-
- Criminal vs. civil court - context, cost dependent.
-
- All todays tests are standard error counters
-
- How many standard errors is the null hypothesis mean away from the
sample mean
-
- If the null hypothesis mean is many standard errors (typically greater than 2) away from the sample mean, then the observed data is not in accordance with the null hypothesis, and we believe the data and reject the null
-
- Types of test
-
- One sample t-test; testing a single population mean, p.131
-
- Two sample t-test; assuming equal variances, p.141.
-
- Two sample t-test; NOT assuming equal variances, p.146. Welsh Anova
-
- Two sample non-parametric tests; NOT assuming approximate normality, p.152. Median + Van der Waerden
-
- Assumptions within groups
-
- Independence
-
- Constant variance
-
- Approximately normal
-
- A measure of the credibility of the null hypothesis
-
- Small p-values give evidence against the null
-
- In English; the probability that if you did the experiment again and the
null hypothesis was true, that you would observe a value of the bf test statistic as extreme as the one you saw the first time.
-
- It picks up the repeatability idea. If something is true (ie the null hypothesis) then you should be able to replicate the observed results. A small p-value says that it would be hard to replicate, hence the small p-value offers evidence against the null
-
- The idea; two repeat observations on the same experimental unit
-
- Twins, feet etc
-
- Controls for unwanted variability between subjects
-
- Essentially a one sample t-test on the differences
-
- Example on p.158
Subsections
2001-09-21